Before anything else, let me start with this:
We’re Not Being Replaced, We’re Evolving
AI isn’t eliminating QA—it’s expanding it. Our work shifts from only validating UI/business flows to shaping data, safety governance and regulation, evaluation, and continuous improvement across the foundation model (FM) lifecycle.
With the right education, skills and methods, us QAs become a force multiplier for building AI products that are reliable, safe, measurable, and human-acceptable.
Why this matters (and why the fear persists)
Over the last two years, AI has accelerated at breakneck speed. Headlines and hype have stoked anxiety about job cuts and particularly in the QA space, the “AI replacing QA”, taglines, didn’t spare us with the scare.
The truth is, as systems become agentic and context-aware, human judgment and guardrails will matter more,not less. And this is where Quality Assurance enters in the grand picture.
I’d like to echo what Andrej Karpathy (originator of vibe-coding term,co-founder of OpenAI) said, the future is agentic + human experts. The two elements are not in competition with each other, but rather complimenting each other, particularly human’s functions and capacities being augmented by agents (AI) – not the other way around.
Quality Assurance is a discipline that has been around since the industrial revolution, and now that we are in the AI revolutionary era, we still have more to contribute, and we are actually an integral “force” to ensure AI developments and applications will operate in not just an exceptional quality standard, but more importantly hold the keys of control and mould these into humanly safe and acceptable technologies.
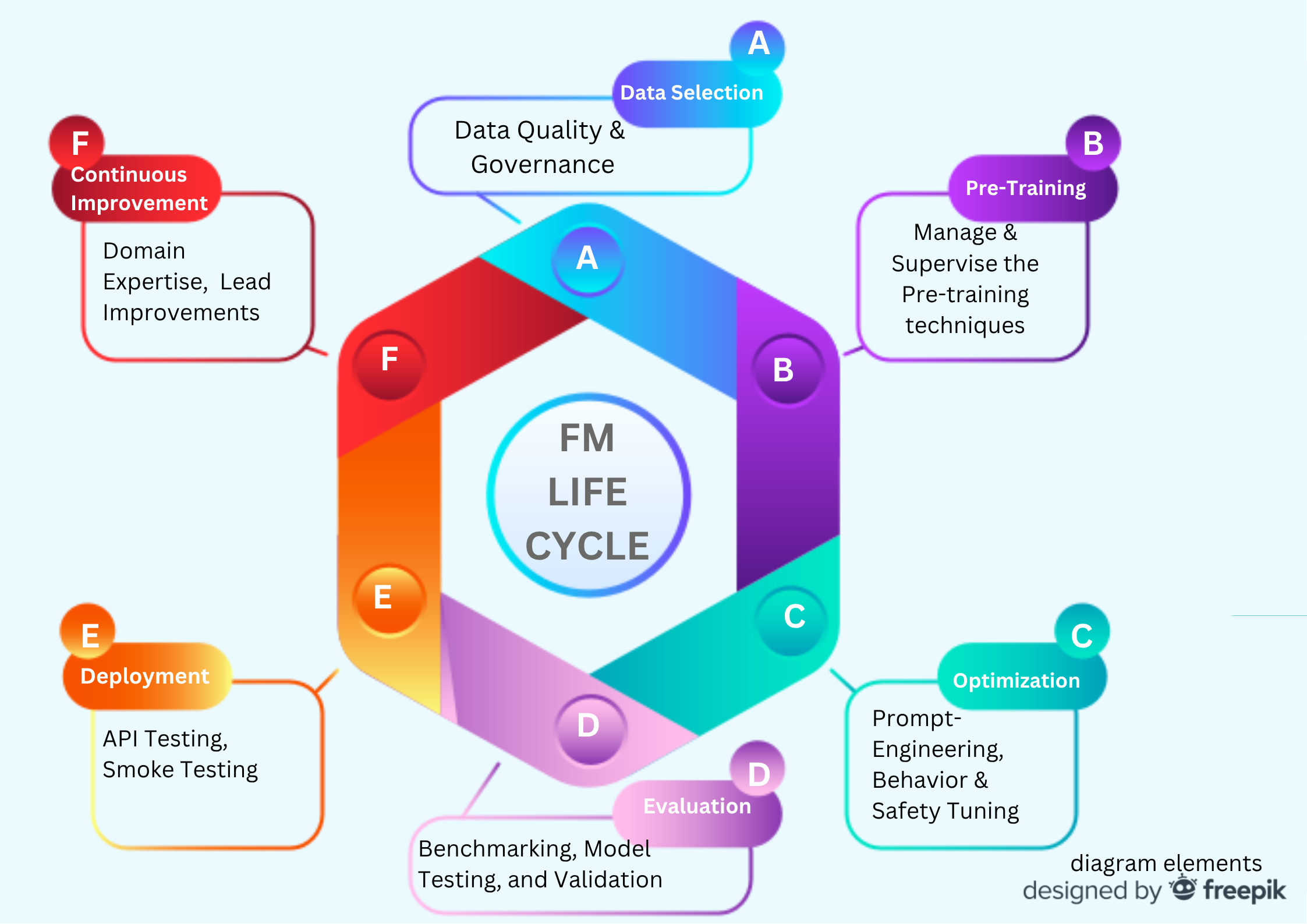
Below is a practical map of where QA fits through the FM cycle and what to deliver at each phase.

The FM Cycle and the QA Layer
1) Data Selection
QA can do:
- Data research & curation: source, sample, de-duplicate, and balance datasets (labeled & unlabeled). ML is only as good as its data, so this is why at the very onset of data collection and selection, QAs can already plug in, and qualify the very data that will feed into the models.
- Labeling & taxonomy: define and categorize label schemas, quality rubrics, and inter-annotator agreement checks.
- Data repository hygiene: versioning, data provenance consent (practice of linking data provenance records with consent records to prove that data was ethically and legally obtained)
- Security Gates: PII/PHI redaction checks, license compliance, and co-owning data quality gates with Data engineers.
2) Pre-Training
QA can do:
- Test planning for pre-training: QA defines success criteria and quality gates for pre-training and verifies them during runs.
- Monitoring and Control: monitor runs, flag anomalies, save test results’ artifacts for later optimization/evaluation.
- RAG groundwork and management: co-design the RAG components with BAs and PMs including management of RAG versions and other relevant documents.
3) Optimization (Fine-tuning / Prompt & Policy Shaping)
QA can do:
- Prompt engineering as test scenarios/cases: encode happy paths, edge/negative cases, and abuse/safety probes.
- RAG alignment: qualify the retrievers and measure top-k relevance against gold answers.
- Reward/scoring: design rubrics for RLHF (Reinforcement Learning for Human Feedback)—define what “good” looks like with scored exemplars and verify the outcomes.
- Data decisions: select/compose labeled data for targeted tasks and improvements.
- Safety Policy and Ethics consistency tests: Designing edge cases intended to mimic a harmful request, worded differently,and verify that the model consistently refuses to affirm the input. (This is where our human judgment particularly our engraved human understanding of morality is highly needed and will play an integral role in shaping responsible and ethical AIs).
Additional note:
The Risk-Based Strategy can be adapted here in designing the test cases for different optimization techniques such as fine tuning, prompt-engineering, and reinforcement learning for human feedback – more on this in my next article!
4) Evaluation
QA can do: design and run the model evaluation system, as well as establish and design the KPIs for measuring the model’s success and correctness.
These are the different categories that we can utilize to score the model:
- Groundedness (citations/references are correct)
- Task success (meets explicit user goal)
- Format correctness (JSON/CSV/API schema adherence)
- Clarity (concise, unambiguous)
- Safety guardrails (policy-consistent refusals)
- Human behavior adaptiveness (helpfulness, tone, instruction-following), safety guardrails adherence)
- Error rate (functional/output errors)
- Inference time (latency bands)
- Hallucination rate (measured against gold truths)
- API testing pass rate(endpoints, retries, idempotency)
5) Deployment
QA can do:
- Production smoke testing across flows (including fallback paths).
- API contract tests (schemas, limits, throttling, error handling).
- Guardrail verification (safety refusals still hold in prod settings).
6) Feedback & Continuous Improvement
QA can do: act as domain stewards and signal routers.
- Human-in-the-loop (HITL): triage real user feedback to gold/gray buckets; create new test seeds.
- Drift & regression monitoring: track quality drift, latency regressions, safety incidents.
- Root cause reviews: collect feedback, transpose as new data, and feed or go back to the training loop.
- Backlog shaping: propose data adds, prompt/policy tweaks, RAG content upgrades.
This is a comprehensive list, and I hope this information encourages us all to stop fearing AI but instead choose to evolve and adapt well with it.
Here’s some suggestions of skills and tools QAs can start learning and upgrading to do so:
AI and ML Literacy (understand the AI fundamentals, FM lifecycle and phases, Optimisation Techniques, Generative AI architectures)
Prompt/test design (structured instructions, edge/negative probes)
Rubric writing (clear scoring definitions; examples of pass/fail)- combine this with the Risk-Based Strategy
Data quality (labeling guidelines, IAA, bias/coverage checks)
RAG literacy (indexing, top-k eval, relevance/QC)
Safety & policy testing (refusal quality, contextual harm detection)
Automation (Playwright/Postman for APIs & UI around model endpoints)
Observability (logs/metrics/traces, ethical data capture)
Statistics basics (confidence, sampling, drift indicators)
Conclusion
AI raises the Quality Bar, its no longer just “does the UI work?”, but more so “does the model behave—reliably, safely, measurably and ethically under real-world pressure?”
Our QA Superpowers of bringing method, evidence,user-centric risk thinking and systems understanding to that question is still relevant and essential.
Definitely, we are not being replaced; we’re moving closer to the center of how AI products are made.

If this approach resonates, my ebook “Risk-Based Testing Playbook” gives you copy-ready matrices, methods, and templates for:
- Risk scoring
- Risk-based test design, prioritisation and reporting
It’s a precise, easy-to-apply guide for teams who need to move fast and safely. If you pick it up and find it useful, a review would mean a lot.
Grab a copy here

If you’re looking for a QA partner for your AI projects, feel free to send me a direct message here, happy to help!
Leave a Reply